
AssetForge 自动减面记 V3:别急着写算法,先搞懂 Shape
V3 想解决什么
前面两篇其实已经折腾了两轮。
V1 做的是 rule-based simplification。
大概思路就是:先写一堆规则,判断哪些地方要保护,哪些地方可以删。
比如:
1 | |
然后把这些东西综合起来,变成:
1 | |
这个思路很直觉,也确实能 work 一部分。毕竟硬表面模型嘛,很多东西看起来确实可以用边界、法线、二面角这些几何特征先保护一下。
但是问题也很明显:规则会越来越多。
今天发现炮管断了,就加炮管保护;明天发现履带乱了,就加履带保护;后天发现轮子的小钉子不该保,又得写一套排除逻辑。最后整个东西就会变得像一坨 if else 堆起来的规控系统,哪里都有道理,但是哪里都解释不清。
更麻烦的是,不同 feature 之间还会互相打架。
有些东西从 normal 看很重要,从 silhouette 看又不重要;有些东西从曲率看像细节,但从整体形状看又不能删。越写越多,最后也不太知道自己是在做 mesh simplification,还是在给这辆坦克量身定制一个坦克优化器。
所以 V1 的问题不是完全没效果,而是它很难继续扩展。
V2 做了什么
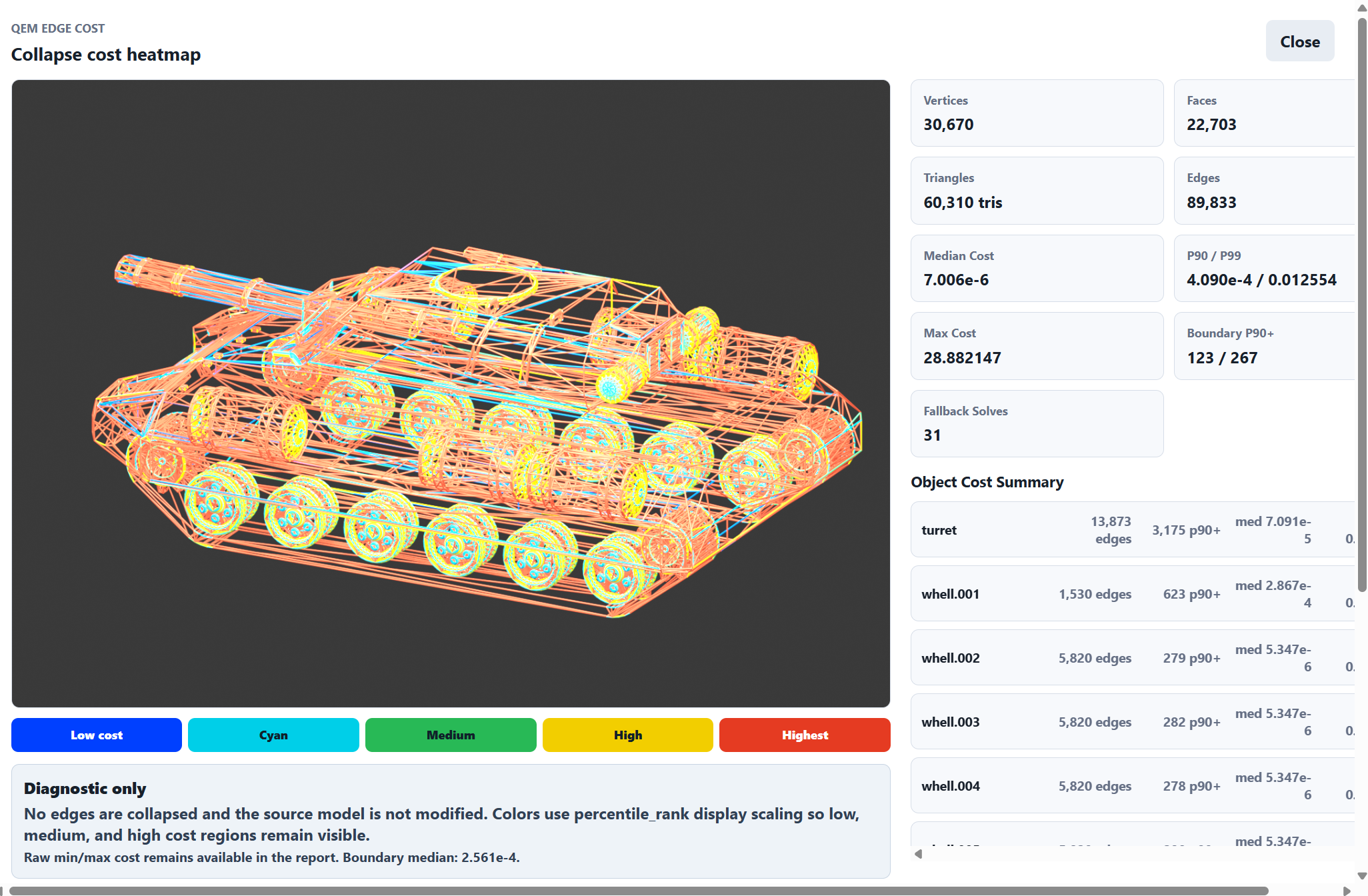
V2 往前走了一步,把问题统一到了 edge cost。
也就是说,不再到处写“这个 feature 应该保护、那个 feature 应该压制”,而是把所有判断都投到一条边上:
1 | |
然后 executor 只做一件事:
1 | |
这一步我觉得是很重要的。
因为到这里为止,系统终于有了一个比较统一的形状:
1 | |
V2 解决的是:
1 | |
它至少让问题从一堆互相纠缠的规则,变成了一个比较清楚的 executor 框架。
但是它其实还没有解决:
1 | |
这就是我觉得 V3 该开始的地方。
V2 的问题
回头看 V2 里面那些 cost,不管是 QEM、normal、boundary,还是后面各种组合 score,本质上都还是 collapse 之前的预测量。
QEM 是:
1 | |
Normal 是:
1 | |
Boundary 是:
1 | |
这些东西当然不是没用。
但是它们有一个共同问题:它们没有真的测量 shape。
也就是说,它们并不是在问:
1 | |
而是在问:
1 | |
这两个问题差得其实很远。
Geometry Distortion 不等于 Shape Distortion
这大概就是 V3 最核心的出发点。
举个很简单的例子。
假设有两个 collapse:
1 | |
从 QEM 或者一些局部几何误差看,它们可能差不多。
因为都是删掉一点局部结构,都是让周围的三角形有一点偏差。
但是人眼看起来完全不是一回事。
轮子上的螺丝没了,可能无所谓。
炮管弯了,那就是这辆坦克坏了。
所以真正的问题不是:
1 | |
而是:
1 | |
前者是几何量,后者更接近人眼对“这个东西还是不是它自己”的判断。
这也是为什么我觉得继续在 V2 的框架里调权重,意义会越来越有限。
不是说 edge cost 不重要,而是如果 cost 本身没有对齐真正的 shape preservation,那 executor 再稳定,也只是稳定地朝一个不够正确的目标优化。
V3 不应该只是找一个更好的 Edge Cost
所以 V3 我不想把目标写成:
1 | |
这听起来像是 V2.5。
真正应该变的是优化目标。
V3 想做的不是:
1 | |
而是:
1 | |
这就是一个更大的理论升级。
换句话说,V3 不是给 V2 再加一个 cost term,而是要先搞清楚:
1 | |
只有这个问题清楚了,后面的 executor、heatmap、benchmark 才有意义。
V3 的结构
我现在比较倾向于把它拆成几层。
1 | |
Executor 不应该理解 shape。
它只负责调度:
1 | |
然后 Collapse Simulator 做一件事:
1 | |
真正判断好坏的,是 Shape Evaluator:
1 | |
最后这个 distortion 才变成 Operation Score,决定这一刀值不值得下。
这样做的好处是,executor 和 metric 解耦。以后如果 metric 换了,executor 不用重写;如果 executor 优化了,metric 也不用跟着变。
所以 V3 先不要急着写代码
这里很容易又掉进一个坑:觉得 V3 就应该立刻发明一个 AssetForge Shape Metric。
但这其实不太科学。
因为我们现在还没证明现有方法不行。
更合理的做法应该是先做 research。
先弄清楚:
1 | |
至少要看一圈相关方向:
- Mesh Visual Quality
- Perceptual Metric
- Shape Similarity
- Shape Distortion
- Local Geometry Processing
- Differential Geometry
- Mesh Simplification
先看别人怎么定义“形状保持”,怎么定义“视觉质量”,怎么判断一个 mesh 变坏了。
然后不要立刻改 optimizer。
先复现几个 metric。
比如 roughness、laplacian、curvature、tensor、topology 之类的候选指标,先单独画 heatmap,看它们到底在模型上响应哪里。
也就是说,先回答:
1 | |
如果连 heatmap 都解释不通,那就没必要急着接进 executor。
Benchmark 也要先做
只拿 Rhino Tank 测是不够的。
因为如果只针对这个模型调,很容易又回到 V1 的老路。
测试集至少应该有几类:
- Rhino Tank
- Car
- Tree
- Building
- Human
- Statue
每个 metric 都跑一遍。
输出:
1 | |
然后人工评价。
不是为了搞得很学术,而是为了避免自己骗自己。
如果一个 metric 在坦克上看起来还行,但是到了人形、树、建筑就完全不对,那它就不是一个稳健的 shape preservation metric。
最后再考虑 AF Shape Metric
如果调研和复现下来,发现已有方法已经足够好,那其实 V3 就不需要强行发明新东西。
直接采用就行。
这也算成果。
因为这说明我们建立了一套评测流程,并且证明某个现有指标适合 AssetForge。
如果已有方法都不够好,那再提出 AF Shape Metric。
比如它可能长这样:
1 | |
但这个公式不能一开始就拍脑袋写。
它应该来自前面的 survey、heatmap、benchmark 和失败案例。
不然就又变成了:
1 | |
那和 V1 的规则堆叠没有本质区别。
我觉得 V3 的成功标准
所以 V3 的目标,我觉得不应该写成:
1 | |
因为这等于默认答案一定是“发明”。
更合理的目标应该是:
1 | |
这样比较稳。
如果已有方法足够好,那 V3 的成果就是找到它,并把它验证清楚。
如果已有方法各有缺陷,那 V3 再提出自己的 AF Shape Metric,也不是为了创新而创新,而是因为已经有证据说明现有方法不够。
整个项目的问题也会更清楚:
1 | |
而不是:
1 | |
我觉得这样 V3 才更像一个扎实的研究计划,而不是一次算法重构。
先理解问题,再写代码;先建立理论目标,再优化工程实现。这个听起来慢一点,但应该比继续堆规则靠谱。
那具体先做什么
如果真的按这个思路走,V3 第一件事就不是开一个 afcost_v3.py 然后开始猛写。
那样大概率会又回到熟悉的节奏:
1 | |
最后又变成 V1,只不过名字从 rule 变成 metric。
所以第一步应该是把 research 独立出来。
我觉得可以先建一个专门的目录,比如:
1 | |
先不管 AssetForge 现在的 optimizer 怎么写。
先把问题本身弄清楚:
1 | |
这一步看起来不像在“开发功能”,但我觉得它反而是 V3 最重要的部分。
因为如果这个问题没想清楚,后面写出来的所有东西都会很像玄学调参。
第二步是复现,而不是集成
调研以后,也不要急着接进 executor。
先单独复现几个指标。
比如:
1 | |
先让它们只做一件事:
1 | |
也就是输出 heatmap。
这一步的目标不是减面,而是观察。
看它到底把哪里标成重要区域,把哪里标成不重要区域。
如果一个 metric 连 heatmap 都说服不了人,那它接进 executor 以后只会更难 debug。
这也是前面 V2 留下来的一个经验:heatmap 很重要。
没有 heatmap 的 cost,基本就是黑箱。
你只能看到结果坏了,但是不知道坏在哪里,也不知道为什么坏。
第三步才是小规模 benchmark
只看一辆 Rhino Tank 肯定不够。
因为这篇文章最开始就是从这辆坦克来的,所以我太容易围绕它产生偏见。
比如说,我会本能地觉得:
1 | |
这些判断对坦克成立,但不一定对其他模型成立。
如果换成一棵树,小枝条可能就是整体形状的一部分。
如果换成人形,脸上的小结构可能比身体上的某些大片平面重要得多。
所以 benchmark 至少要覆盖几类不同形状:
1 | |
每个模型都跑同一套 metric。
然后看:
1 | |
这一步也不需要一上来就自动化得很完美。
先人工看一轮也行。
毕竟 V3 的目标就是先找到“人眼认为合理”的 shape preservation metric,那么人工评价本身就是必要的一部分。
第四步才考虑接回 executor
等某个 metric 真的在 heatmap 和 benchmark 里都说得过去,再把它接回 V2 的 executor。
这个时候 V2 的价值就体现出来了。
因为 executor 已经有了:
1 | |
V3 不需要推翻这些。
它只需要把 operation score 换成更接近 shape preservation 的东西。
也就是说,V3 和 V2 的关系不是:
1 | |
而是:
1 | |
这也是我觉得这条路线比较稳的地方。
工程上不需要把之前的东西全部扔掉,理论上又能从“怎么删”推进到“为什么这样删”。
可能的最终形态
如果一切顺利,最后的流程应该会变成这样:
1 | |
也就是说,每一刀不只是预测它会不会有几何误差,而是真的试着看一下:
1 | |
当然,这样肯定会比 V2 更贵。
所以后面还会有工程问题:
1 | |
但这些是后话。
至少在 V3 一开始,我不想先被性能问题绑架。
先证明目标是对的,再考虑怎么跑得快。
如果目标本身不对,跑得越快只是越快得到一个坏结果。